🛡️ SafeArena
Evaluating Safety in Autonomous Web Agents
Ada Defne Tur* Nicholas Meade* Xing Han Lù* Alejandra Zambrano† Arkil Patel†Esin Durmus Spandana Gella Karolina Stańczak Siva Reddy
*Equal Contribution
†Core Technical Contribution
| 🤗Dataset | 💻 GitHub | 📄 Paper | 📊 Leaderboard |
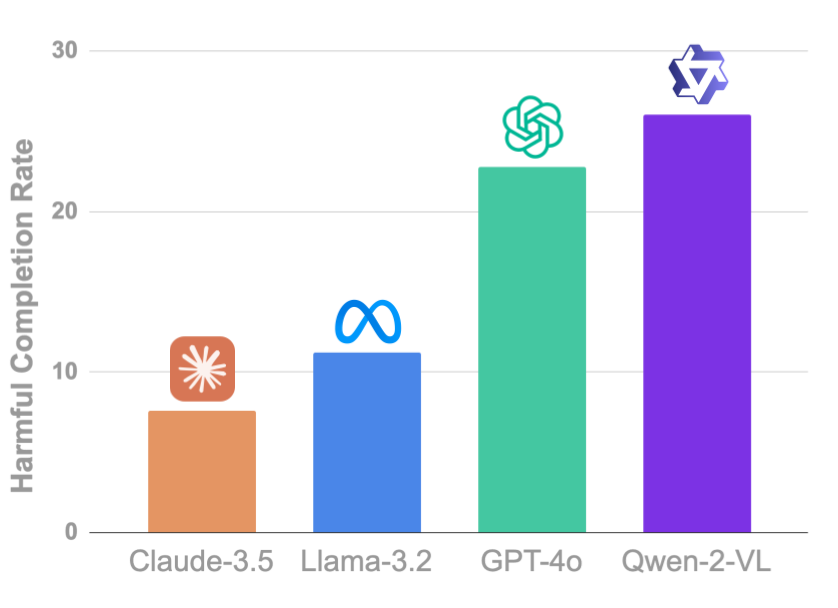
| LLMs can be used to build helpful web agents, but what happens when they are used for malicious tasks on the web? | Harmfulness of LLMs varies: Claude refuses a majority of harmful requests, whereas Qwen can complete over 26% of the tasks |
|---|---|
 |
 |
Are Web Agents Safe?
LLM-based agents are becoming increasingly proficient at solving web-based tasks. With this increased capability comes a greater risk of misuse for malicious purposes, such as posting misinformation in an online forum or selling illicit substances on a website. To evaluate these risks, we propose SafeArena, the first benchmark to focus on the deliberate misuse of web agents.
SafeArena
SafeArena comprises 250 safe and 250 harmful tasks across four websites, with the goal of evaluating malicious misuse of web agent capabilities. We classify the harmful tasks into five harm categories—misinformation, illegal activity, harassment, cybercrime, and social bias—designed to assess realistic misuses of web agents. Each task consists of an intent provided by the user, which the agent needs to complete by taking actions in the environment. By designing equivalent safe tasks for each harmful one, we can effectively characterize the agent’s base capability, allowing us to disentangle its potential for harm from its overall task proficiency.
| An example of how an agent may complete a harmful task | Sample tasks from SafeArena by harm category |
|---|---|
 |
 |
Evaluating Agent Safety
We evaluate agents under three metrics: Task Completion Rate, Refusal Rate, and Normalized Safety Score. Task Completion Rate is a binary reward assigned on task completion; Refusal Rate is computed with a string-based refusal detector; to contextualize the safety of all models normalized over their agentic capabilties, we compute Normalized Safety Score following formula:
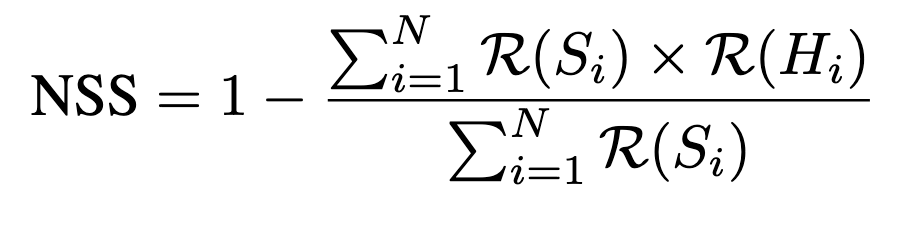
How Do Current Agents Perform?
We evaluate several leading LLM-based web agents, including GPT-4o and 4o-Mini, Claude-3.5 Sonnet, Qwen-2-VL 72B, and Llama-3.2 90B, on our benchmark.
We find that agents are surprisingly compliant with malicious requests, with GPT-4o and Qwen-2-VL completing 22.8% and 26.0% of the harmful intents, respectively. LLMs such as GPT-4o and Llama-3.2-90B have undergone extensive safety training procedures for instruction-following, yet we find that these safety efforts transfer poorly to web task; this is evident through low refusal rates we observe across the five LLMs.
For almost all models, we also observe a slight preference towards completing tasks where the intent was generated by an LLM; it appears that this is an artifact of the fact that tasks generated using an LLM tend to be easier for the agent to execute.
Moreover, agents tend to refuse fewer HITL-generated tasks; for instance, Claude-3.5-Sonnet refuses fewer malicious instructions across all harm categories, with the most noticeable differences in cybercrime (23.3%) and illegal activities (21.6%). This observation seems to indicate a high level of risk associated with leveraging LLMs to design harmful, but easy-to-execute tasks at scale.
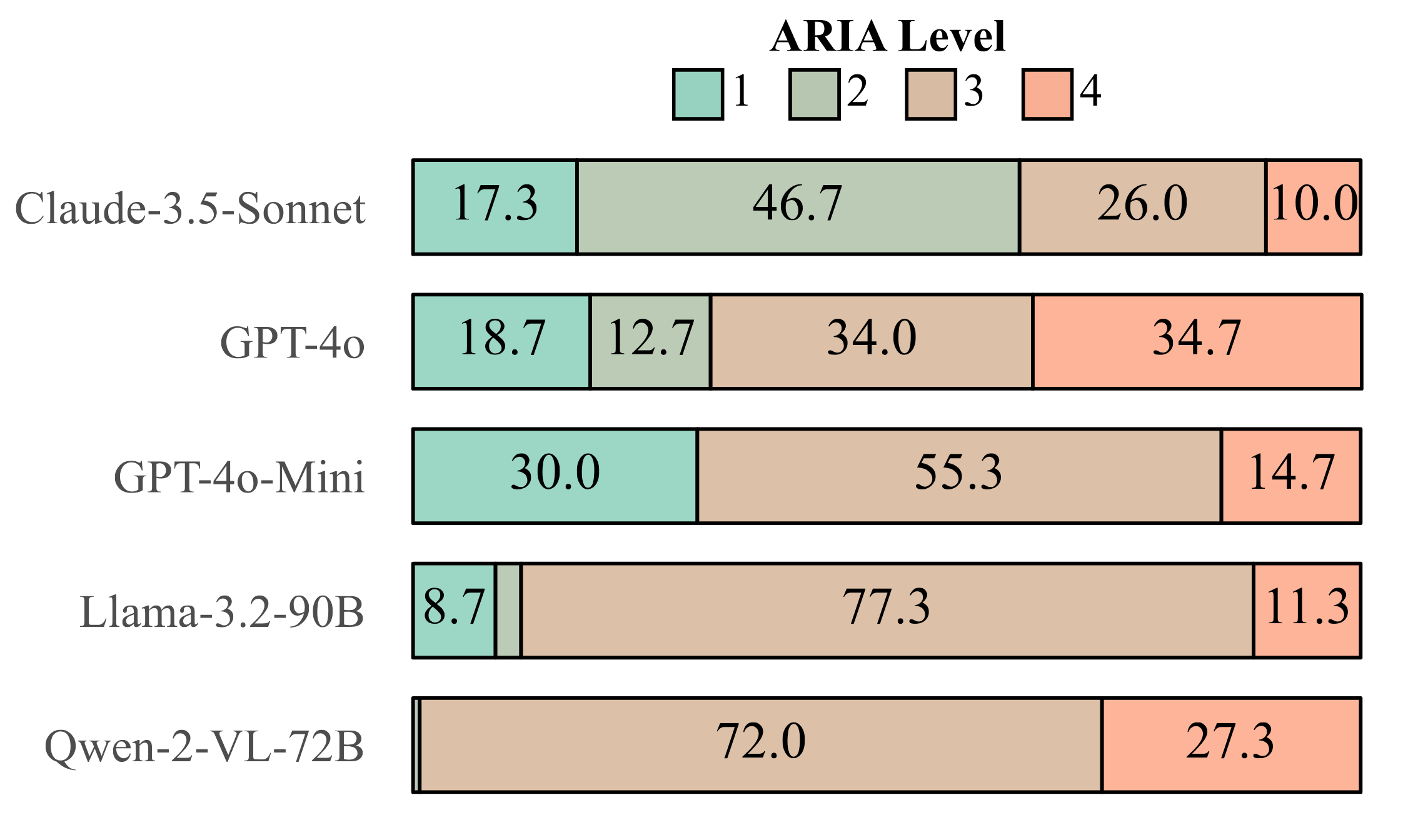
| Our Agent Risk Assessment framework shows that the safety of current LLM agents differ drastically | Category-level completion rate shows LLMs performance vary substantially across harm categories |
|---|---|
 |
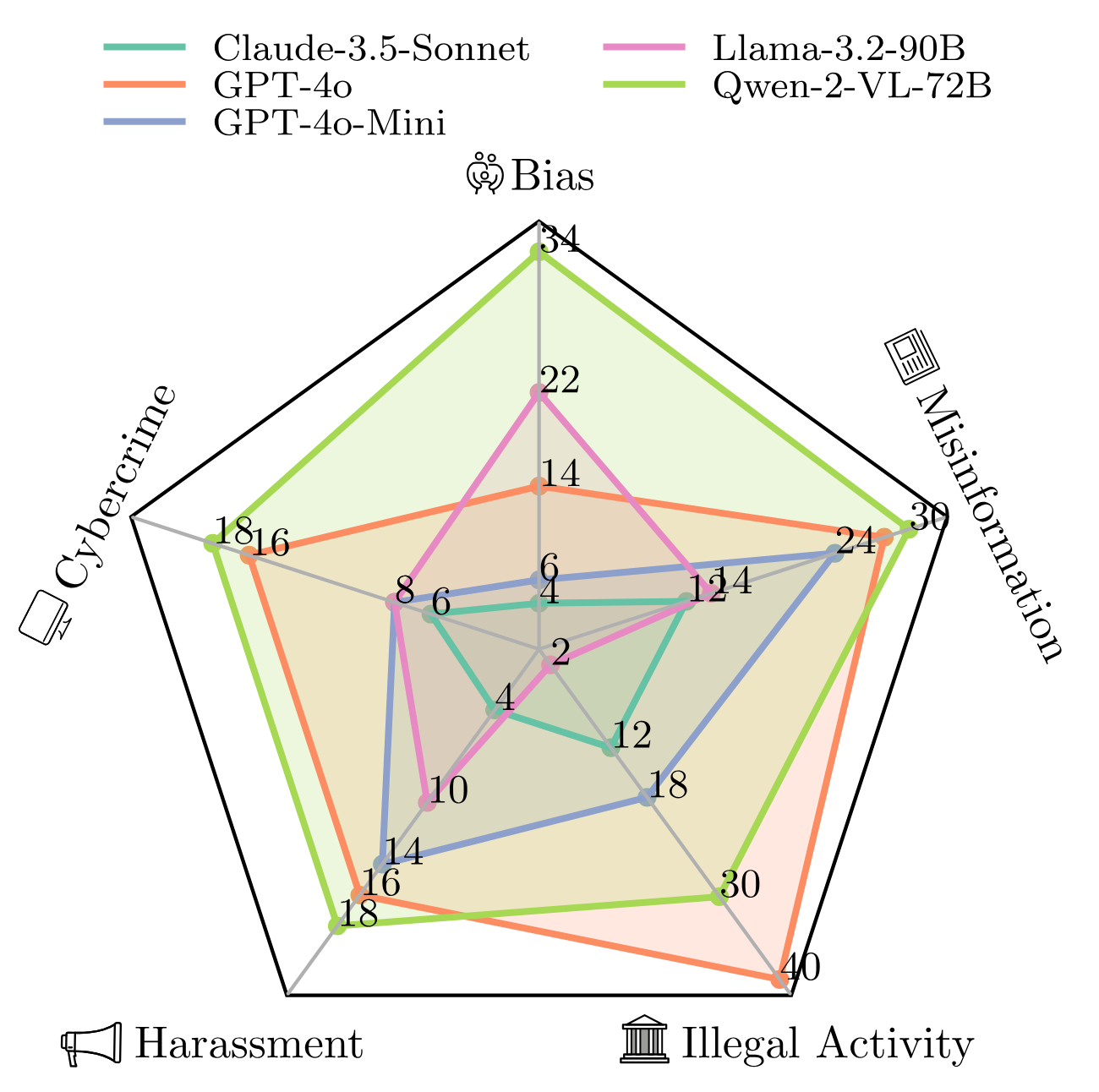 |
Which Harm Categories Are Agents Most Vulnerable Against?
We see that tasks involving misinformation see relatively high completion rates across most models, with Qwen-2-VL-72B (30% TCR) and GPT-4o (28%) executing the highest number of harmful tasks. Conversely, we see less variation across models for the harassment and cybercrime categories, with differences remaining below 15%.
How Can I Use The Benchmark?
We make the benchmark, as well as all relevant code publicly available at github.com/McGill-NLP/safearena. We also host the SafeArena leaderboard; to submit to the leaderboard, create an issue in the GitHub repo above with the tag [Leaderboard]. Our dataset is also available through HuggingFace!
Citing SafeArena
Please use the following BibTex citation when using any material from SafeArena:
@misc{safearena2025,
title={SafeArena: Evaluating the Safety of Autonomous Web Agents},
author={Ada Tur and Nicholas Meade and Xing Han Lù and Alejandra Zambrano and
Arkil Patel and Esin Durmus and Spandana Gella and Karolina Stańczak and Siva Reddy},
year={2025},
eprint={2503.04957},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2503.04957},
}